
この記事のまとめ:
- CourseraのDeep Learning専門講座のコース5: Sequence ModelsのWeek 2の受講メモとして、要点とよくわからなかったところを補完のために調べたことなどを備忘録としてまとめています。
- Week 2では、自然言語処理におけるWord Embeddingと感情分類を学びます。
コース5:Sequence Modelsについて
このコースでは、再帰型ニューラルネットワーク(Recurrent Neural Networks)の基本的なネットワーク構成と、応用例として自然言語処理におけるWord Embeddingや感情分類、機械翻訳、音声認識について学びます。
3週間の内容は次の通りです。
Week 2の概要
このコースのWeek 2では、下記のことについて学びます。
- 自然言語処理におけるWord Embedding表現
- Word2VecアルゴリズムとしてのSkip-gram、GloVe
- Negative Sampling
- 感情分類
- Word Embedding表現のバイアス除去
Word Embeddings
単語はone-hotベクトルで表現してきました。この表現では単語間の類似性を表すことが難しいです。そこで、Word Embedding (単語埋め込み)、あるいはDistributed Representation(単語分散表現)というものがあります。
Word Embeddingでは各単語を特徴量としてベクトル表現します。例えば、単語を表現するために300個の特徴量があれば300次元のベクトルとなります。また、ここではそのベクトルを、 のように表現します。
例えば、“man”、“woman”、“king”、"queen"という単語の関係を、Word Embeddingにおいては、この特徴ベクトルを使って次のように表すことができます。
したがって、Word Embeddingにおける単語のベクトル間の類似性は、単語間の意味的類似性を表します。
また、"man"と"woman"という関係性に対して、"king"に対応する単語を探すこともできます。探索したい単語を とすると次のように表すことができます。
これはコサイン類似度が最大となるベクトル が単語 を探索するという意味です。
t-SNE
300次元の特徴量が類似しているかどうかを視覚的に確認することは難しいかもしれません。そんな時にはt-SNEアルゴリズムを活用して次元圧縮して平面グラフ化することができます。詳細は下記が参考になります。
Embedding Matrix
Word EmbeddingにおけるEmbedding Matrixを とし、辞書のone-hotベクトルを で表すと次のように表すことができます。
Word2Vec
上記のEmbedding Matrix を得るための手法としてWord2Vecアルゴリズムがあります。ここではその中でもSkip-gramというアルゴリズムを見ていきます。
Skip-gramでは、文脈のコンテンツ から、目的となる単語 を予測することを行います。すなわち、事後確率として次のように表せます。
ここで、 は目的となる単語 に対応するパラメーターです。また、 は辞書全体を指しています。
ここまでをニューラルネットワークで表すと次のようになり、非常にシンプルなネットワークです。
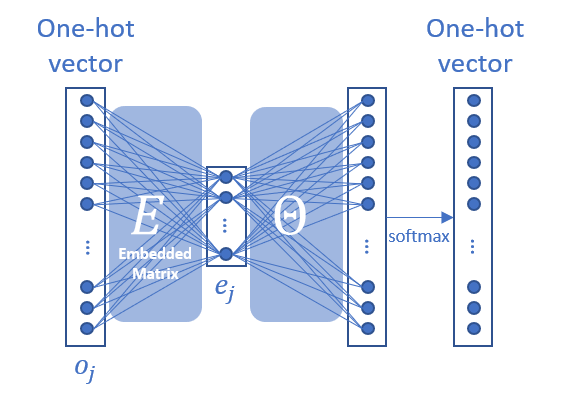
損失関数は通常のSoftmax関数の時と同じで次のようになります。
Negative Sampling
上記のやり方では、softmax関数の計算の際、辞書のサイズが一般的には非常に大きいため、計算コストが非常に大きいです(特にsoftmax関数の分母の総和計算)。そこで、多項分類問題から二項分類問題に変換することで計算コストを下げるための手法がNegative Samplingです。
これまでは、入力として文脈のコンテンツ から、目的となる単語 を予測することをしてきましたが、Negative Samplingでは、入力として、 のペアを入力として、 が目的としているペア ()か、そうでない () かを予測するモデルに変換します。つまり、次のように表せます。
なお、 はシグモイド関数です。
学習時においては、 となる単語だけでなく、 となる単語も入力辞書からランダムに 個抽出する必要があります。ランダムに抽出する際、論文では下記に分布に従って単語 を抽出することを推奨されています。
また、論文では、 は非常に大きいデータの場合には2~5個、小さいデータセットの場合には5~20個を推奨されています。
Skip-GramとNegative Samplingについて、下記も参考にさせていただきました。
元の論文は下記をご参照ください。
GloVe (Global Vectors for word representation)
Skip-Gramよりも新しいWord EmbeddingのアルゴリズムとしてGloVeがあります。GloVeでは文脈 の中に目的とする単語 が出てくる回数 を使います。この を使って、特徴ベクトル を生成することを目指します。
GloVeアルゴリズムでは、次の最小二乗誤差のモデルを最適化することで を得ます。
ここで、 は重み項であり、高頻出の単語の値を小さく、低頻出の単語の値を大きくするためのものです。また、 のときに とし、 計算でエラーとならないようにするための関数です。
感情分類 (Sentiment Classification)
感情分類の大きな課題は、ラベル付きの訓練データが多く存在しないことです。唯一使える情報として、お店や商品などのレーティングなど文章があります。そういった学習を行うモデルとしてRNNを使う方法があります。
次のように各単語を特徴ベクトル化し、そのベクトルをmany-to-oneのRNNに入力します。出力 は1~5などのレーティング情報に該当します。RNNで学習することで否定語などの場合などにも正しく学習することができます。

Word Embeddingのバイアス除去
機械学習やAIアルゴリズムによって重要な判断を行う機会は日に日に増していると思います。そういった場合において、アルゴリズムから期待しないバイアス (例えば性別のバイアスなど) を取り除きたい場合があります。その方法についてここでは見ていきます。
ここでは性別のバイアスを例にバイアスの除去の方法をみていきます。
- バイアスの方向を特定する
性別を表す単語のペア (例えば、“he"と"she”、“male"と"female”)の特徴ベクトルの差を取ることで性別のみを示すベクトルが得られます。この処理を複数の単語のペアで平均化します。
- バイアスを除去する
本来性別を表さない単語でかつ学習結果として性別のバイアスがかかった単語から"1."で得られた性別を示すベクトルを引きます。ここで、どのようにバイアスを除去する単語を選ぶかという課題があります。本論文では、そういった単語自体を学習して抽出しようとしています。
- ペアを等化する
"1."で使用した単語のペアのそれぞれは、"2."でバイアスを除去した単語とのユークリッド距離は同じであるはずです。したがって、"1."で得たベクトルを軸として、バイアスを除去した単語とのユークリッド距離が同じになるように補正します。
今回は以上です。 最後まで読んでいただき、ありがとうございます。
CourseraのDeep Learning専門講座の他のコースの受講メモ
- コース1: Neural Networks and Deep Learning
- コース2: Improving Deep Neural networks
- コース3: Structuring Machine Learning Projectsについて
- コース4: Convolutional Neural Network

{kind=link}
コメントを投稿